


Thinking about Data Types
In this article I want to discuss the types of problems that can appear around using data types. I also argue for some up-front planning when using key data types in your application. Finally, I introduce protobuf, the cross-language data type generator from Google.
Data types vary from language to language and implementation to implementation but they generally consist of the following variations:
- Simple types like integers (signed, unsigned, bytes, 16-bit, 32-bit, etc.)
- “Sort of” simple types like characters and strings (8-bit or unicode). I say “sort of” because “here be dragons” going back and forth between unicode.
- Enumerated types
- Collections of multiple types using keys (dictionaries and maps) or no keys (structures and unions)
- Arrays (multiple sequence of a specific type)
As long as you code in one particular language at a time, the language does the heavy lifting for you with respect to data types. You might need to spend a moment to explicitly define them (C++, C, Java, C#, Actionscript) or you might get away without defining them at all and let the compiler do it for you (Python, Lua). In all these cases you only need to worry about data types during edge conditions, like signed vs. unsigned conversions, bit manipulations, or math precision.
So generally data types don’t need to enter your awareness too much. This can lead to a, shall we say, “organic” growth of the use of data types in your application. That is, you create them as you need them while programming and may not necessarily plan out their long-term use. “Long-term” applies to data that has longevity in your application as opposed to temporary variables.
Problems occur when these data types need to be marshalled or unmarshalled. Marshalling is the process of converting types from one form to another (and unmarshalling converts them back), usually for transmission of some sort.
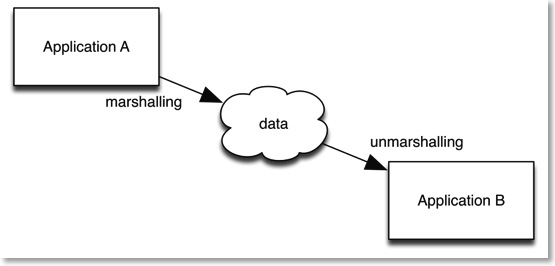
There are many examples of marshalling in regular programming:
- Saving and retrieving data to/from files.
- Communication boundaries between two languages. A very common example of this is the regular conversion between C++ and C-style strings. Other examples exist when connecting to a scripting language (like Lua scripting as an enhancement to applications like video games).
- Communication through pipes or sockets.
- Communication between processes or threads.
- Client/Server communication.
- Conversion to/from XML.
Marshalling is a messy process. It’s messy because you’re dealing with unprotected data from untrusted sources. The data is unprotected in that the compiler no longer has control of the data once it has been marshalled (turned into the cloud below). Normally a compiler prevents invalid data from being inserted into data types (depending on the language more or less protection).
The data is untrusted because once it crosses your application boundary you cannot know what happens to it in transit. If something happens to the data the unmarshalling process may not work and cause exceptions. Due to all this uncertainty, you need to build some form of verification into the unmarshalling process to make sure you have good data coming into your application.
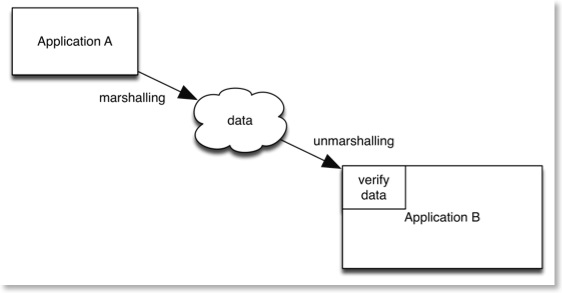
You also have versioning issues. You may decide to change the format of the data or add extra properties (for example, adding extra items to a dictionary). You then need to deal with the older format of the data which may exist in older deployed applications or files. Even if you intend to upgrade all these interfaces quickly there is still a transition period where you need to deal with two different formats.
There are many other problems as well:
- Endian issues deal with non-byte numbers being represented in a different sequence on different types of processors.
- Numbers may be different byte sizes on each side of the marshalling.
- Strings may only be 8-bit on one side of the marshalling and unicode on the other.
All of this highlights that you need a strategy for dealing with interface-critical data types. Some of this is handled through web services like SOAP or JSON, but these aren’t always available to you (or you may not wish to use them), especially when working with embedded applications.
A relatively recent alternative comes from Google. Protobuf (Protocol Buffers) is an open source language independent format for defining data types. A .proto file specifies the data types. Protobuf then generates the data types in the language of your choice.
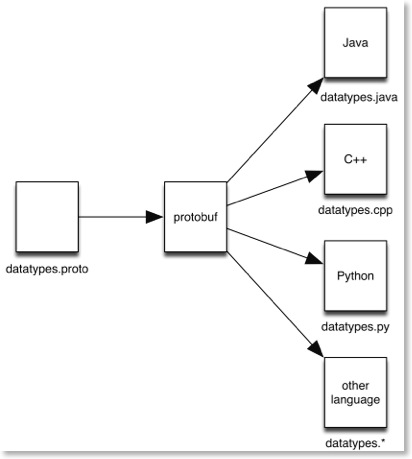
Protobuf officially supports Python, C++ and Java. There are a host of third party extensions for other languages, including C#, C, and Actionscript.
Protobuf features versioning as well as simple data verification during marshalling. The language independence ensures that you can write language independent data types and continue to use them should you need to expand into a different language in the future. The Google documentation has a good explanation on protobuf’s marshalling efficiency as well.
I encourage you to check out protobuf for your next project. It solves many problems you may have not known were there and would rather not encounter. You honestly do not want to build these things from scratch.
You have better things to do.
You may like to see the mindmap that was used to write the draft of this entry. Please click on the map below for a bigger picture.
